Сайт на Node.js и Express своими руками
Вписываем название торрента, жмем Enter и в ту же секунду под списком появляются результаты. Жмем на «глобус» и начинается загрузка. Да, вы угадали: это заключительная статья из серии «Готовимся к закрытию Rutracker», в которой мы рассмотрим создание простого сайта на Node.js. Первая часть тут, вторая тут.
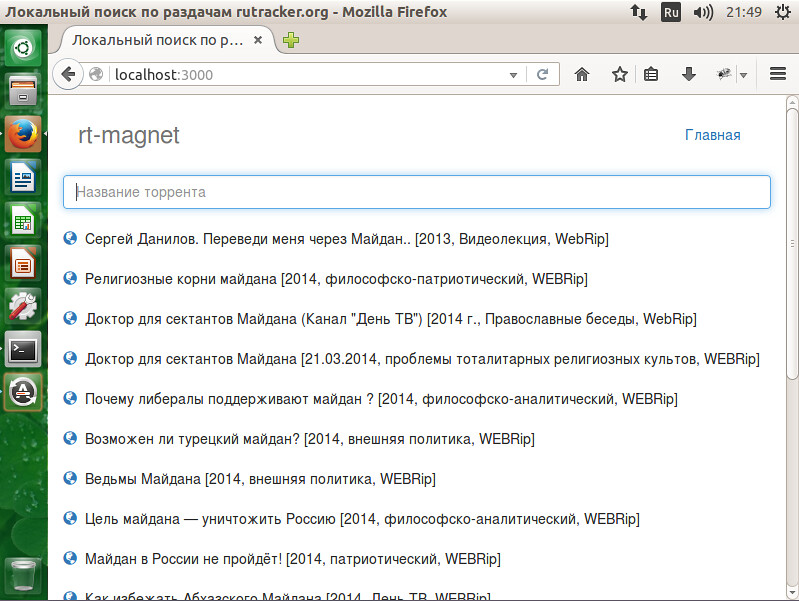
Начнем традиционно с вопросов и ответов.
Вопрос: зачем так много всего ради торрентов?
Ответ: торренты тут просто для примера. Я люблю осваивать новые технологии и считаю, что лучше тренироваться на чем-то реальном, нежели писать очередной бесполезный Hello World. С JavaScript я начал знакомиться 3 дня назад и эта статья — побочный продукт этого знакомства.
Вопрос: зачем нужен Apache Solr и MySQL одновременно?
Ответ: я привел примеры того, как можно организовать поиск. Solr и MySQL устанавливать параллельно не нужно. Вы можете выбрать что-то одно. Например, если у вас уже поднят MySQL, то будет логично использовать его. Если вы хотите не только искать по торрентам, но и проиндексировать содержимое своей домашней директории, то лучше использовать Solr.
Вопрос: можно ли обойтись вообще без программирования?
Ответ: можно. Solr использует библиотеку Apache Tika, которая умеет определять тип контента и извлекать данные. Вы можете просто скормить Solr всю директорию с CSV-файлами целиком, а Tika сама всё распарсит.
А теперь переходим к Node.js.
Что такое Node.js?
Как-то раз любознательные экспериментаторы выдернули из браузера Chromium движок Google V8, отвечающий за обработку JavaScript, перенесли его на сервер и попытались использовать исключительно клиентский доселе JavaScript в серверных целях, для создания сайта. Каково же было их удивление, когда получившийся сайт уделал по производительности сайты, построенные по всем остальным технологиям сайтостроительства, включая этот ваш PHP. Исследователи обрадовались, назвали свое изобретение Node.js и стали его раскручивать. В наши дни Node.js уже используют такие небезызвестные компании, как Uber, PayPal, LinkedIn, New York Times и другие.
Почему Node.js уделывает другие платформы разработки? На это есть три причины:
- Node работает в режиме сервера приложений. Например, сайт на PHP для сборки каждой страницы каждый раз загружает PHP-файлы, интерпретирует их, обрабатывает инклюды, каждый раз заново устанавливает соединение с базой данных и запрашивает из нее повторно объекты. Node запускается только один раз, устанавливает одно соединение (или пул соединений) с БД, инициализирует рабочие объекты и потом начинает обрабатывать входящие HTTP-запросы один за другим, не прерываясь.
- Вторая причина заключается в самом языке JavaScript. Он асинхронный. Это значит, что функции выполняются не последовательно, а параллельно. Таким образом, скрипт отрабатывает быстрее и Node способен обслужить больше соединений в единицу времени. Вот за что полюбили Node.js на высоконагруженных сайтах.
- Сам движок написан очень качественно и сильно обгоняет все остальные JS-движки.
Но довольно слов, оценим скорость Node.js на практике. Чтобы сократить объем программирования, воспользуемся замечательным фрэймворком Express. Фрэймворк сгенерирует все файлы за нас и вся работа сведется к редактированию 2 файлов: один JS-скрипт на клиентской стороне будет отсылать AJAX-запросы к БД, другой JS-скрипт на сервере будет на эти запросы отвечать. AJAX можно было бы и не использовать, но мы же ходим оценить производительность Node, поэтому работа без перезагрузки страницы будет весьма кстати.
Чтобы было интереснее, не будем создавать ни форму, ни кнопки. Только одна строка с текстовым вводом вне тега form. Не знаю, насколько это соответствует стандарту HTML5, зато стильно, модно, молодежно: юзер пишет запрос, нажимает Enter и сразу же видит результат.
Сначала клиентская часть:
var torrentDbQuery = function() {
// Возьмем запрос из формы
var query = $('#torrent-name').val();
// И отправим get-запрос серверу
$.ajax({
method: 'get',
url: '/ajax/search',
dataType: 'json',
data: { query: query }
// Тут проявляется асинхронность. Интерпретатор не будет дожидаться получения ответа
// от сервера и перейдет к выполнению следующих команд. Но нам-то хотело бы всё же получить
// результат и обработать его. Запилим анонимную функцию и укажем, что ее нужно будет выполнить
// после того, как сервер ответит.
}).done(function(r) {
if (r.status === 'ok') {
// Очистим поле ввода для нового запроса
$('#torrent-name').val('');
// Удалим старые результаты поиска
$('#results').empty();
// Переберем массив, который вернул сервер и покажем результаты поиска
r.data.forEach(function(torrent) {
$('#results').append('' +
'' +
' ' +
torrent.name +
'');
});
} else if (r.status === 'fail') {
$('#torrent-name').html('Error: ' + r.message);
} else {
$('#torrent-name').html('Кажется, что-то пошло не так');
}
});
}
Теперь серверная часть, которая обрабатывает AJAX-запрос:
router.get('/search', function(req, res, next) {
// Что там запросил пользователь?
var q = req.query.query;
// Сформируем SQL-запрос
q = q.split(' ').join("%' and name like '%");
var query = "select name, magnet from torrents " +
"where name like '%" + q + "%'";
// И запросим. Вторым аргументом функции указывается анонимная функция,
// которая будет вызвана после того, как данные будут извлечены из БД.
// Это опять та самая асинхронность, которая дарует скорость. (Но и возможность
// легко "прострелить себе ногу" тоже дарует).
db.query(query, function(error, row) {
if (error) {
res.json({ status: 'fail', message: error });
} else {
res.json({ status: 'ok', data: row });
}
});
});
Запускаем и проверяем:
npm start

Вписываем запрос (кстати, местные интеллектуалы могут попытаться угадать по результатам выдачи, какой именно запрос я ввел).

Работает. И результат появляется впечатляюще быстро. Но «впечатляюще» — это сколько в миллисекундах? Давайте посмотрим:

154 миллисекунды. И это при том, что Node был запущен в режиме отладки. Но быстрее ли это PHP? Я переписал серверную часть на PHP с использованием самого шустрого фрэймворка Slim и запустил Apache Benchmark для сравнения. Но об этом в одной из следующих статей, а то я уже немного утомился графоманствовать.
Хочу такой поиск, но не хочу программировать
Тогда можно воспользоваться готовым решением:
git clone https://github.com/pomodor/rt-magnet.git
cd rt-magnet/web
npm install
npm start
Если база не была создана ранее, скачиваем свежий архив раздач тут и запускаем скрипт import.rb из директории import.
Комментарии
Чингачгук
28 ноября, 2015 - 16:56
ни одного коммента, все усердно пытаются воспроизвести написанное :) Думаю пока торрент еще на плаву, еще все не так суетятся. Потом будет аврал. Спасибо автору за посты, щас я тоже начну экспериментировать.
pomodor
28 ноября, 2015 - 17:24
Да, статьи о пакостях в W10 вызывают лавину комментариев, а как только пытаешься написать что-то полезное, народ встречает апатией. Вот уж действительно, хлеба и зрелищ. :)
Но Гитхаб показывает, что 7 человек всё же клонировали проект. :)
Чингачгук
29 ноября, 2015 - 00:03
можно для чайника поподробнее...
pomodor
29 ноября, 2015 - 02:28
Конечно! Какую часть пояснить?
jtad
29 ноября, 2015 - 14:23
я тоже сижу разбираюсь с solr, первый раз о нем слышу. Установить и запустить было просто, но потом... Мне вообще такие вещи нравятся, но я тормоз, на все надо время :). В инете на русском на удивление мало инфы, на англицком хоть и читаю, помогает часто только метод научного тыка. Ваш ранний пост оказался очень полезным http://liberatum.ru/blog/solr-rss, спасибо.
pomodor
29 ноября, 2015 - 18:56
Solr быстро развивается, документация не поспевает, поэтому много неточностей.
Вот моя короткая инструкция:
1. Скачиваем и распаковываем Solr. Заходим в полученную директорию, а потом в bin.
2. Стартуем сервер:
./solr start
3. Создаем ядро. Тут есть нюанс: создать через Web-админку Solr не получится, хотя там и есть такой пункт. Создаем из терминала:
./solr create_core -c mycore
4. Теперь индексация. Для этого предназначен скрипт post из состава Solr. Им можно проиндексировать, например, содержимое своих документов или всей домашней директории. Ну, либо, директорию с csv-файлами с Рутрекера запихнуть.
./post [-c название ядра] [директория]
Всё. Теперь можно искать миллионом различных способов. Можно из своего скрипта, можно из админки Solr, можно просто воспользоваться браузером, скормив ему ссылку с запросом.
Чингачгук
29 ноября, 2015 - 10:59
какие пакеты должны быть установлены в системе ? где должна находится база торрентов ? (директория , папка). готовое решение выполняется от пользователя или от root ?
pomodor
29 ноября, 2015 - 18:26
Без разницы. После отработки скрипта import.rb файлы можно удалить.
Разумеется, никакого рута. Админские полномочия потребуются только для установки зависимостей через apt-get.
Первым делом, git. Он нужен для загрузки исходников. Да и вообще это крайне полезная вещь.
apt-get install git-core
Но можно и отказаться. Нужно зайти на GitHub и нажать "Download ZIP".
Потом потребуется Ruby для работы скриптов:
apt-get install ruby
Потребуется MySQL:
apt-get install mysql-server mysql-client
И Node.js:
apt-get install nodejs
Чингачгук
30 ноября, 2015 - 18:55
Для успокоения несправившихся, и просто если кому не хочется устанавливать лишние пакеты.
Подобное вполне можно наговнокодить на пхп, с нулевыми знаниями и доступом к гуглу. Я так делал. Просто нужен был результат, при похожей задаче — сделать поиск по базе.
А так, зачетная статья. Не думаю, что буду использовать библиотеки в будущих прикладных проектах, но по крайней мере это полезно и применимо к офигенной куче сценариев, не только к злободневному рутрекеру.
jtad
30 ноября, 2015 - 23:59
абсолютно согласен, если кто работает в ит (да и не только) такой мощьный бесплатный поисковик не может не пригодиться, знания никогда не бывают лишними. Не думаю что кто не справился, установка явы и solr вообще примитивщина. Использование поисковика было потруднее, спасибо автору за статьи и комментарии многое прояснило. Сам делаю на яве, очень интересно
Чингачгук
1 декабря, 2015 - 21:01
просветите Уважаемые , при запуске import.rb вот такой выхлоп
./import.rb:10: invalid multibyte char (US-ASCII)
./import.rb:10: invalid multibyte char (US-ASCII)
./import.rb:10: syntax error, unexpected $end, expecting keyword_end
puts './import.rb <директория с файлами csv>'
как понимаю это что-то с кодировкой ?
pomodor
1 декабря, 2015 - 21:38
Под Windows что ли запускаете?
Чингачгук
1 декабря, 2015 - 22:19
mint 17. на этом же диске стоит win7. может из-за этого ?
pomodor
1 декабря, 2015 - 23:41
Добавьте второй строкой в import.rb:
# encoding: utf-8
Если заработает, то у вас старая версия Ruby. Узнать номер версии можно так:
ruby -v
Комментировать