R для продвижения сайта на Drupal
Как с помощью языка R проанализировать статистические показатели сайта на Drupal и увеличить количество посещений.

Идея, заложенная в основу
Сайт — совокупность отдельных страниц. Страница может быть популярной и привлекать посетителей, а может быть непопулярной. Если разбить страницы на кластеры и выделить признаки удачных статей, то можно будет писать больше хороших и меньше плохих. В свою очередь, это приведет к общему росту количества посещений.
Drupal + R + RMySQL = любовь
R имеет очень развитые возможности импорта/экспорта. Данные из MySQL можно экспортировать в формате CSV и потом загрузить в R. Но добрые люди написали библиотеку RMySQL, позволяющую напрямую подрубиться к работающему сайту и снимать статистику в режиме реального времени.
Устанавливаем:
install.packages("RMySQL")
И подключаемся:
library(RMySQL)
m <- dbConnect(dbDriver("MySQL"), dbname="liberatum", "username", "password")
Теперь можно создавать датафреймы в R напрямую из таблиц в MySQL.
Как Drupal хранит информацию о посещениях
Каждая страница сайта в терминологии Drupal зовется узлом (node). Метаданные об узлах содержатся в таблице node, тело страницы в node_revisions, а статистическая информация о просмотрах в node_counter. Объединяем таблицы и грузим в R:
select node.nid, title, totalcount, daycount from node left join node_counter on node.nid = node_counter.nid
Проверяем, все ли верно загрузилось и в той ли кодировке:
head(t)
nid title totalcount daycount
1 2 Эффекты коммерциализации open source сообществ 2693 0
2 3 Аналитическая оценка свободного ПО 2873 1
3 4 Индекс репутации LRI 1975 0
4 5 Индекс репутации LRI за февраль 2008 года 8094 3
5 6 Sun и Microsoft укрепляют партнерские отношения 2218 0
6 7 Какую операционную систему выбрать? 21143 4
Графики популярности
Получена информация о 12012 узлах. Строим график популярности узлов в зависимости от идентификатора узла (в практическом смысле, это будет изменение популярности статей по времени).
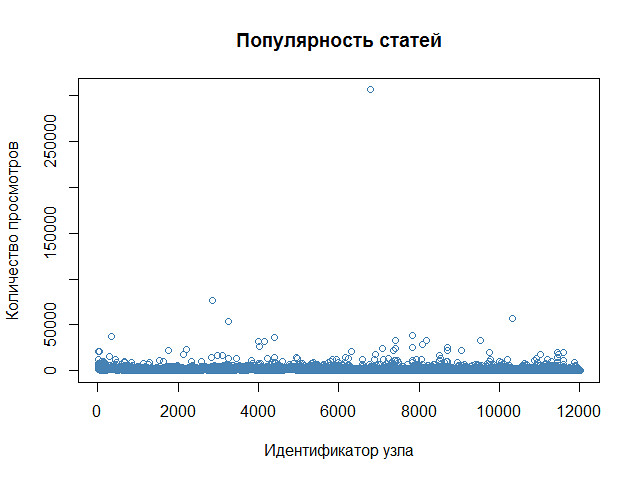
На картинке можно увидеть три условные группы: обычные статьи, удачные статьи и одиночный «выброс» с 300 тыс. просмотров. Конечно, было бы интересно ориентироваться на эту сверхуспешную группу, но поскольку в ней всего один элемент, изучению статистическими методами эта группа не поддается и интереса в рамках данной статьи не представляет.
Кластеризация
Разобьем узлы на кластеры. Кластеров будет, как выяснили выше, три:
K-means clustering with 3 clusters of sizes 1, 11948, 63
Cluster means:
[,1]
1 305810.000
2 1532.976
3 21231.508
В первый кластер попала одна статья с количеством просмотров 305810, во второй кластер вошла основная группа статей (со средней популярностью около 1,5 тыс. просмотров). Наконец, в третий кластер — он для нас и представляет интерес — вошли 63 статьи со средним количеством просмотров 21 тыс. Если выявить характерные особенности статей из второго и третьего кластера (если они вообще существуют), то теоретическим можно будет использовать эти отличия и писать статьи, которые будут почти в 14 раз более эффективны. Это при условии полного учета всех факторов, что на практике едва ли достижимо. Но и «скромный» рост эффективности в 2-3 раза меня бы вполне устроил.
Посмотрим на картинку:
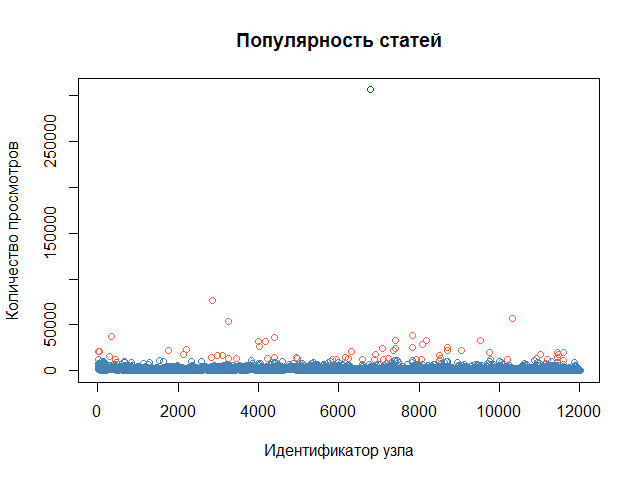
Упрощенно говоря, конечной целью работы должно стать увеличение оранжевых кружков за счет уменьшения синих.
Откуда берутся просмотры страниц
Чтобы перейти к анализу, необходимо сначала задуматься, а откуда вообще у каждой статьи берутся просмотры? Я бы выделил два главных источника: поисковые системы и прямые заходы (сюда же можно отнести RSS-подписчиков). Понятно, что на разные источники влияют разные факторы. Для «прямых» читателей основной фактор — заголовок. Если он привлек внимание, читатель перейдет по ссылке и откроет статью. Другими словами, надо анализировать, в первую очередь, заголовки: ключевые слова, длину, количество знаков пунктуации и т.д. Для переходов с поисковиков заголовки тоже важны, но еще важнее факторы ранжирования самой поисковой системы. Из тех, на которые мы можем повлиять это: ключевые слова в заголовке и теле статьи, использование (или не использование) разных тегов, наличие картинок, ссылок, видео и т.д. По этим критериям и нужно искать отличия статей из второго и третьего кластера.
Чтобы не утомлять читателя, проанализируем лишь ключевые слова в заголовке и его длину.
Ключевые слова популярных статей
Строим облако слов по заголовкам популярных статей:

Вроде бы, все ясно. Но радостно кидаться писать статьи и включать в заголовки эти ключевые слова рано. Мы ведь искали отличия, то есть характерные особенности. Поэтому, строим еще облако слов из заголовков «обычных» статей и ищем ключевые слова, входящие в первое облако, но отсутствующие во втором. Строго говоря, полное отсутствие и не требуется, достаточно, чтобы частотность слова во втором облаке была ниже.

Ну вот, теперь можно делать кое-какие выводы. Хочу сразу предупредить, что для реального анализа надо стоит строить таблицы, а не картинки. Так будет проще находить пересечения и считать частоты.
Итак, включение в заголовок слов «как» и «ubuntu» повышает вероятность того, что количество просмотров будет выше среднего. Еще людей привлекает «установка» чего-либо и последующее «ускорение».
Какие слова не использовать в заголовке
Теперь посмотрим, какие темы являются изначально провальными. Я предлагаю следующий алгоритм: берем статьи из второго кластера (основной) и отфильтровываем те, у которых количество просмотров ниже среднего в пределах кластера. Снова строим облако слов и отбрасываем те, которые характерны для всего кластера.

Можно вывести правило: хочешь испортить статью, пиши об интернете, пользователях, России и политиках.
Оптимальная длина заголовка статьи
Теперь посмотрим, зависит ли популярность статьи от длины заголовка.
Дополним таблицу столбцом с длиной и построим график:
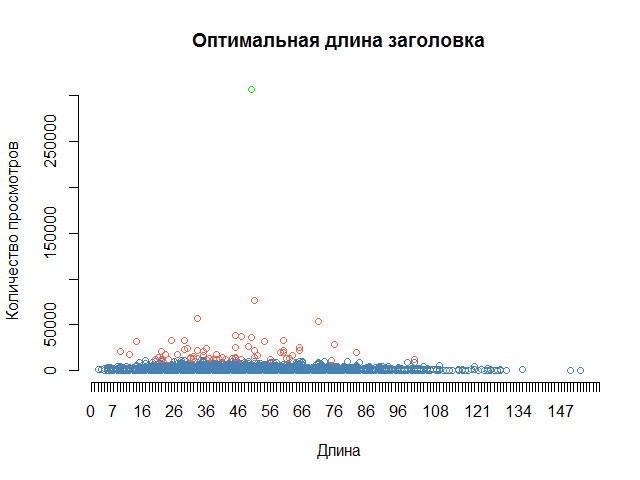
Сложно не увидеть закономерность: длинный заголовок снижает шансы на успех практически до нуля. Но какой конкретно диапазон длин является оптимальным? Лучше гистограммы никто на этот вопрос не ответит:
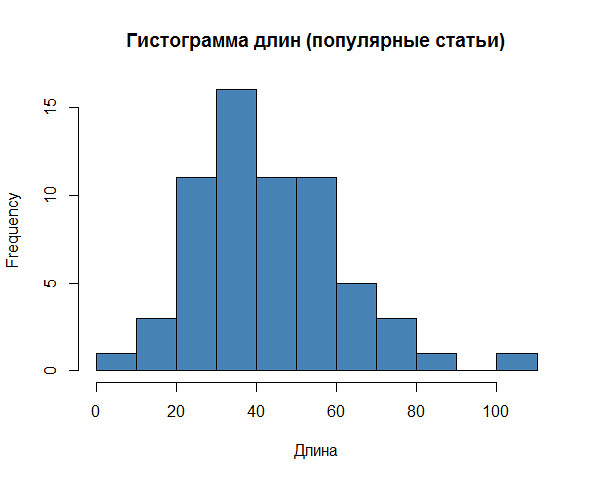
Короткий заголовок (20-60 символов) — ключ к успеху.
А что дальше?
Можно выделить как можно больше характеристик и написать модуль для Drupal, который прямо во время написания статьи будет примерно оценивать шансы на успех размещаемого материала.
Комментировать