Как Linux и R помогли мне заработать на Forex
Язык программирования R — настоящая жемчужина из мира Open Source. Одной из любопытных областей применения этого языка является анализ временных рядов, построение статистической модели и прогнозирование. Попробуем скрестить ужа с ежом R с MetaTrader 4, чтобы стать валютным спекулянтом и как следует нагреть руки на кризисе.
Первым делом нам нужно поставить MetaTrader 4. Это такая проприетарная программулина, через которую можно покупать/продавать валюту. Работает только под Windows, поэтому придется запускать через Wine.
Устанавливаем Wine и пробуем запустить MT4. Ничего не получается. Оказывается, что разработчики Debian 7 сделали неприятный сюрприз пользователям 64-битной версии дистрибутива. Дело в том, что пакет с Wine под эту архитектуру есть, а внутри пакета — только заглушка, которая поздравит пользователя с тем, что у него 64-битная ОС и откажется работать дальше. Придется добавить i386 в список поддерживаемых архитектур. Очень неприятно, но что делать? Никто не обещал, что королем валютных спекуляций стать легко:
sudo dpkg --add-architecture i386
sudo apt-get update
sudo apt-get install wine:i386
Будет установлен 32-битный Wine, который сразу же полюбил MT4. Всё работает. И без единого разрыва, прошу заметить.
Что нам потребуется?
Нам требуется передавать котировки из MT4 в R, строить прогноз, рисовать график (исключительно для эффектности), принимать решение (покупать/продавать/ждать) и передавать данные обратно в MT4. Обмениваться данными, учитывая кроссплатформенность, можно 3 способами:
- через файл;
- через СУБД;
- через сокет.
Все способы хороши, но сперва надо проверить концепцию, поэтому пока ограничимся самым простым способом — через экспорт котировок в файл.
Экспорт котировок из MetaTrader 4
Жмем F2, берем пару евро/доллар, поминутные котировки и экспортируем. Программа разрешит сохранить только 65000 последних цен, но нам этого хватит с избытком.
Импорт котировок в R
Языку R хоть и сто лет в обед, тем не менее, это высокоуровневый язык, объектно-ориентированный и очень прогрессивный даже по современным меркам. Например, на нем написан фреймворк Shiny, на котором можно запилить сайт. Да такой, что поклонники модных штучек типа Angular обзавидуются, ну а пэхэписты вообще удавятся.
Не будем отвлекаться. Язык высокоуровневый, поэтому импортировать таблицы на нем — одно удовольствие. Грузим таблицу с котировками из файла (она, забыл сказать, в формате CSV):
t <- read.table("eur.csv", sep=",", header=F)
Опции означают следующее: имя файла — eur.csv, разделителем полей служит запятая, заголовка у таблицы нет.
Теперь в переменной t хранится таблица из 7 колонок и 65000 строк. Столбцы следующие: дата, время, цена открытия, максимум, минимум, цена закрытия, объем.
V1 V2 V3 V4 V5 V6 V7
64991 2015.01.19 21:48 1.16056 1.16065 1.16047 1.16062 63
64992 2015.01.19 21:49 1.16063 1.16064 1.16026 1.16026 58
64993 2015.01.19 21:50 1.16026 1.16034 1.16025 1.16026 40
64994 2015.01.19 21:51 1.16026 1.16031 1.16024 1.16030 30
64995 2015.01.19 21:52 1.16029 1.16055 1.16027 1.16055 35
64996 2015.01.19 21:53 1.16055 1.16062 1.16052 1.16061 23
64997 2015.01.19 21:54 1.16062 1.16063 1.16032 1.16032 55
64998 2015.01.19 21:55 1.16033 1.16041 1.16033 1.16036 33
64999 2015.01.19 21:56 1.16036 1.16036 1.16021 1.16023 31
65000 2015.01.19 21:57 1.16022 1.16023 1.16014 1.16021 25
Обзовем столбцы, чтобы не запутаться в дальнейшем:
names(t) <- list("date","time","open","max","min","close","volume")
И проверим:
tail(t,1)
date time open max min close volume
65000 2015.01.19 21:57 1.16022 1.16023 1.16014 1.16021 25
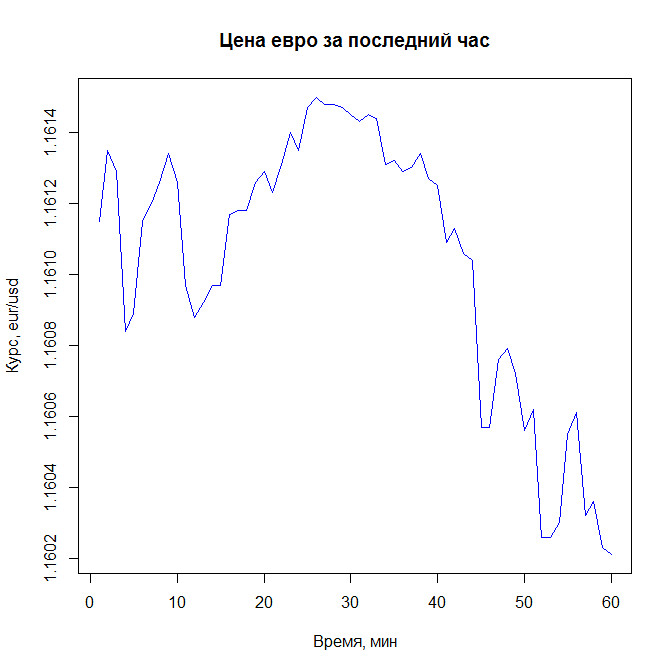
Вся таблица очень важна, но пока нас интересуют только цены закрытия. Возьмем столбец close, извлечем 60 последних значений (за последний час) и преобразуем вектор (так называется массив в R) во временной ряд (time series в R).
c <- ts(tail(t$close,60))
Проверим:
is.ts(c)
[1] TRUE
length(c)
[1] 60
Да, переменная c имеет тип ts (временной ряд) и состоит из 60 наблюдений. Строим график:
plot(c,col="blue",main="Цена евро за последний час",xlab="Время, мин",ylab="Курс, eur/usd")
Получаем:
Что надо знать успешному валютному спекулянту
Данные загружены и проверены, давайте займемся анализом. Итак, что нам надо узнать:
- долгосрочный тренд;
- краткосрочный тренд;
- прогноз;
- амплитуда цен;
- профит по прогнозу.
Прошу меня простить за мерзкое слово из лексикона Димона. Правильно говорить не тренд, а тенденция. Но в эконометрике так уж исторически сложилось, что тенденция зовется трендом, а тенденция, выраженная в графическом виде, зовется trend line.
Тренды бывают следующие (зацените откуда инфо по ссылке):
- линейными;
- логарифмическими;
- полиномиальными;
- степенными;
- показательными;
- на основе скользящего среднего;
- и так далее.
В Метатрейдере широко используется скользящее среднее. Есть даже масса торговых стратегий на основе этой трендовой линии. Например, если цена выше линии, значит «рынок перегрет» — надо продавать. Ниже линии — покупать. Стоит ли говорить, что скользящее среднее — бред собачий, а стратегии на нём — кратчайший путь к разорению.
Настоящие пацаны используют полиномиальную линию тренда. По умолчанию ее нет в MT4, но можно поискать на стороне. Я не нашел. Есть только инструкции по скрещиванию MT4 с R.
Но не будем отвлекаться. Итак, нам нужно построить две полиномиальные линии тренда. Для этого нужно рассчитать коэффициенты полинома. Можно рассчитать вручную, но не забывайте, что мы загрузили минутные цены и решение желательно принять в течении минуты, иначе картина может измениться. Поэтому, воспользуемся силой языка R.
Поставим пакет Practical Numerical Math Functions:
install.packages("pracma")
Команда install.packages — аналог apt-get install в Дебиане/Убуке. Думаю, тут все понятно.
Теперь рассчитаем коэффициенты полиномов:
len <- length(t)
x <- seq(to=len)
p2 <- polyfit(x,t,2)
y2 <- polyval(p2,x)
Это для второй степени. Точки для графика в (x,y2).
Прогнозирование валютных котировок
Сила R — в прогнозировании. Гении математики уже реализовали все алгоритмы, заботливо запаковали всё в пакеты и оставили пользователю только кнопку «Заработать бабло». Например, в R есть пакет nnet (neural network), предназначенный для построения собственной нейронной сети. Искусственный интеллект можно заставить выполнять задачи классификации, кластеризации и прогнозирования. Для R есть пакет forecast (прогнозирование), содержащий миллион алгоритмов прогнозирования на все случаи жизни. Есть статистические модели «из коробки». Например, популярнейшая у спекулянтов ARIMA.
Как правильно выбрать модель для прогнозирования котировок
Правило тут одно: перебирай передовые стратегии и тестируй их на исторических данных. Подбирай параметры.
Думаю, не стоит говорить, что 100%-й точности добиваться не обязательно. Способность предсказывать котировки с точностью 51% принесет вам миллионы (при условии наличия достаточного стартового капитала и при условии, что ваша стратегия не умрет раньше, чем вы успеете купить яхту, фазенду на юге Франции и длинноногих красавиц, которые будут пропалывать на вашей фазенде грядки с петрушкой).
Делайте ваши ставки, господа!
Но довольно мечтаний, переходим к делу. Прежде всего, закатываем всё набранное выше в функцию forex(). Торговать предполагается на минутных интервалах, поэтому времени на обработку данных не будет. Получил котировки, запустил forex(), открыл позицию.
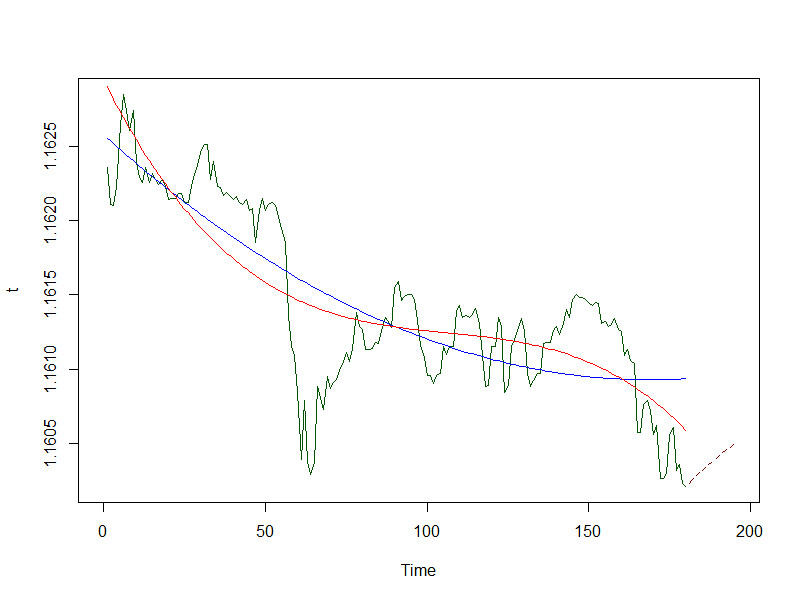
После запуска forex() получаем график:

Кстати, зачем нам понадобились линии тренда? Одно из базовых правил игры на бирже гласит: нечего переть против линии тренда, самый умный шоле? Следуй за рынком, а не борись с ним. С другой стороны, если все будут следовать, то откуда же возьмется прибыль (напомню, на Форексе прибыль одного = проигрыш другого)? Поэтому, будем учитывать долгосрочный тренд, но попрем против краткосрочного, если на то укажет наш прогноз. На графике видно, что пока позиции открывать не стоит, хотя все продают, а прогноз на рост.
Еще очень важный момент: амплитуда, спред и профит. Если посмотреть на график, то можно заметить, что прогноз обещает рост. Но какой? Дополним функцию forex() расчетом потенциальной прибыли. Получаем:
t <- forex()
range: 0.00138
profit: 0.0003857743
Даже если мы пойдем против тренда и прогноз окажется верным, прибыль составит 3 пункта, тогда как спред (разница между курсами покупки и продажи на бирже) — 4. Надо нам такое?
Еще один график:
Линия долгосрочного тренда демонстрирует нам, что падение заканчивается, краткосрочный тренд продолжает показывать падение, прогноз в плюс. Надо открывать длинную позицию. (Вообще-то не надо, так как profit пока опять меньше спреда, но это я для примера).
Сведем дебет с кредитом
Я залил на биржу 150 долларов для экспериментов. 7 удачных сделок, 2 в минус. Прибыль за два дня экспериментов — 1370 рублей. Не так много. Но в качестве бонуса годится. Сейчас собираюсь почитать больше книг по R и увеличу депозит до 2 тыд. Об успехах проинформирую общественность отдельным постом. Ах да, забыл, использовал однослойный персептрон, ариму, авторегрессию и половину методов из forecast.
Приятно осознавать, что от изучения R может быть денежный профит, помимо профита в виде знаний. Изначально я стал учить R для того, чтобы понять, как осуществляется кластеризация новостных данных. Но жизнь прекрасна, удивительна и часто дарит сюрпризы в виде неожиданных денежных бонусов. Осваивайте технологии, пишите свои программы и созидайте. Вселенная возблагодарит вас.
;)
Комментарии
comrade
20 января, 2015 - 10:02
Полиномы по точкам проходят?.
Осторожно!
Такая апроксимация может давать ложные выбросы.
Попробуйте апроксимацию сплайнами (тоже полиномы, но более толково проведённые:-)
pomodor
22 января, 2015 - 11:53
Что за ложные выбросы? И при чем тут аппроксимация? Трендовая линия используется для того, чтобы быстро оценить общее направление движения цены, приближение как раз вредит.
comrade
22 января, 2015 - 14:39
Хорошо – интерполяция... :-)
pomodor
22 января, 2015 - 14:45
Интерполяция — нахождение промежуточных значений. Интересно было бы узнать, какие промежуточные значения Вы предлагаете узнавать, если на графике и так минутные цены? :) Отдельные тики что ли?
robomakerr
25 января, 2015 - 12:07
Интересный пост, спасибо.
А можно ли увидеть результат теста вне обучающей выборки?
И есть ли у вас понимание, что делает итоговая модель? Или она — просто смесь методов, красиво звучащих, но выбранных наугад? :)
pomodor
26 января, 2015 - 12:41
Другими словами, не обезьяна ли я? ;) Нет, коэффициенты модели я рассчитывал, а не брал просто от балды произвольные числа.
95% всего «веселья» в статье не отражено. Сначала нужно изучить временной ряд, построить коррелограммы, проверить на стационарность, привести к стационарному виду, рассчитать параметры модели, протестировать, посчитать остатки, проверить их на нормальность и так далее. Я не стал об этом писать, так как цель заметки — привлечь внимание к R, а не отпугнуть сложностью.
В смысле? Обучающей кого? ARIMA же — не нейронная сеть.
robomakerr
26 января, 2015 - 14:52
А, значит всё же ARIMA, а не «половина методов из forecast» :) Тогда вопрос о понимании снимается :)
Обучающая — на которой производилась настройка модели.
pomodor
26 января, 2015 - 15:05
ARIMA описана в статье, но я пробовал и другие модели. Возможно, как-нибудь расскажу о них, хотя и не знаю, нужно ли это кому-то, кроме пары человек. Тут все любят только статьи из серии «Ой, как же мне нравится Убука».
Нет такого понятия. Модель можно идентифицировать и диагностировать. Настраивать там нечего.
robomakerr
26 января, 2015 - 15:15
Ну ок, «настройка» = «расчет коэффициентов» :) Вопрос же не о терминах :)
pomodor
26 января, 2015 - 15:35
Не разобравшись с понятийным аппаратом, невозможно двигаться дальше.
robomakerr
26 января, 2015 - 16:21
Не думаю, что здесь что-то непонятно. Я использовал понятийный аппарат практически дословно из учебников:
machinelearning . ru/wiki/index . php?title=Выборка
"Обучающая выборка — выборка, по которой производится настройка (оптимизация параметров) модели зависимости."
Вы в комментарии упомянули что «нужно... рассчитать параметры модели."
Вопрос был о тесте на данных, которые не использовались для расчетов — я понял так, что его увидеть нельзя?
pomodor
26 января, 2015 - 16:41
Увидеть, разумеется, можно. Но специально я эти данные не сохранял. Когда вернусь к экспериментам, то смогу предоставить Вам данные по диагностике модели. Но хочу еще раз подчеркнуть, что никаких обучающих и тестовых выборок для ARIMA не существует. Почитайте дальше статью, из которой выдернули определение:
Понятно же, что это относится только к нейронным сетям. Какое может быть переобучение у авторегрессии?
robomakerr
26 января, 2015 - 17:04
Почему же только к сетям? Любая модель эксплуатирует некую зависимость (закономерность) в данных. Если в будущем эта зависимость исчезнет, модель работать перестанет. Об этом и речь.
"Обучение» там понимается в более широком смысле, как построение любого алгоритма вообще.
pomodor
26 января, 2015 - 17:12
Потому, что на обучающую и тестовую выборки делят только тогда, когда существует само обучение. В случае нейронных сетей под обучением понимают, например, алгоритм обратного распространения ошибки и подстройку весовых коэффициентов. Тут понятно для чего нужна тестовая выборка. А для авторегрессии как Вы представляете алгоритм обучения? А что понимаете под тестированием «вне обучающей выборки»? Ну, можно построить прогноз и сравнить с реальными данными, которые не использовались для «обучения» (по вашей терминологии). Это Вы имеете ввиду?
robomakerr
26 января, 2015 - 17:34
Допустим, вы идентифицировали некую модель на данных за 2013 год.
А потом пытаетесь ее же идентифицировать на данных за 2014.
pomodor
26 января, 2015 - 18:49
Эээ... А зачем? :) Построив модель, можно переходить к прогнозированию.
robomakerr
26 января, 2015 - 19:05
Затем, что если на 2014 вам ее подтвердить не удастся, то в 2015, ставя деньги на ее прогнозы, на длинной дистанции вы их потеряете практически гарантированно :)
Если б так всё было просто, математики давно бы заработали все существующие деньги на планете :)
pomodor
26 января, 2015 - 19:33
У Вас явно неверное представление о прогнозировании временных рядов. То, что Вы описываете — невозможно. Почитайте про доверительный интервал и поймете почему.
robomakerr
26 января, 2015 - 19:45
Доверительный интервал не меняется :) Я же не предлагаю прогнозировать на год вперед :) Речь идет о сохранении работоспособности модели.
Ладно, дискуссия стала бесполезной и утомительной. Спасибо.
pomodor
26 января, 2015 - 20:00
Да, действительно, термины «ставя деньги» и «длинная дистанция» превращают разговор о прогнозировании временных рядов в нечто, похожее на прием букмекерских ставок на биатлон.
Ну-ну.
Дебаты надо действительно завязывать, но раз уж уже нарисовал картинку... Модель, построенная на два года вперед по годичным данным будет выглядеть примерно так:
pomodor
28 января, 2015 - 13:30
Не успел я написать, что R — это круто, как вышла новость: Microsoft купит дистрибьютора языка статистического программирования R. ;)
Чингачгук
22 июня, 2016 - 16:32
писал диплом по прогнозированию временны рядов в экономике теперь думаю как монетизировать полученные знания, практическую часть тоже делал при помощи R.
спасибо за интересную статью.
pomodor
23 июня, 2016 - 00:34
К сожалению, никак. Надо понимать, что игра на бирже — это всегда игра против кого-то. Деньги не появляются сами собой. Твоя прибыль — это чьи-то потери. А кто будет играть против тебя? Помимо любителей, это корпорации и конторы, которые могут позволить нанимать в штат лучших математиков с докторскими степенями и элитных программистов. У них мощные датацентры. Кто имеет большие шансы в этой схватке? Для многих такая "монетизация" оканчивается разорением.
jtad
23 июня, 2016 - 11:48
чтобы делать деньги нужны деньги :) Богатые фирмы или люди могут повлиять на колебание цен — а значит и форекс ихний. Особенно если такие люди как мы пытаются торговать в долгосрочной перспективе. Логика большинства проста — при хорошем движении по тренду мы отодвигаем стопы чтобы удержаться при колебании цены. Что и используют фирмы чтобы эти стопы посшибать. Без больших денег на форексе делать нечего.
Чингачгук
27 июля, 2016 - 02:05
При таком подходе, ты, Пьер, будешь не только Безуховым, но и ещё Бескапиталовым... :)
Чингачгук
28 декабря, 2016 - 20:26
Ради любопытства, проверил множество разных методов, которые используются для прогнозирования временных рядов, применительно к биржевым котировкам. В большинстве случаев результат прогнозирования очень близок по значению к текущей цене. Но направление движения цены в следующий интервал редко угадывается. Естественно резкие скачки цен на новостях или при вливании свежих денег в рынок прогнозирующими методами не угадываются. Если кому интересно, могу привести соответствующие графики и скрипты на языке R.
pomodor
28 декабря, 2016 - 21:37
Я это уже проходил. Они хорошо угадываются, если собирать новости с лент и вычислять частотность ключевых слов в определенном контексте. Тогда можно получать хорошие результаты. Я даже написал программку, которая складывает ленты в базу PostgreSQL, считает частотность ключей по времени и потом R ищет корреляцию с котировками с учетом лага.
Чингачгук
29 декабря, 2016 - 19:06
Это интересная тема, нечто подобное пытался сделать в Матлабе. Для R встречал скрипты для выуживания информации из Twitter, но там есть сложности. Глубоко пока не вникал, знаю что есть packages для работы с текстами. Буду пробовать. А что касается предсказаний по историческим данным, то тут есть серьезные сомнения. Нет там закономерностей, поэтому построение и использование моделей на исторических данных мало что дает.
pomodor
29 декабря, 2016 - 19:24
В Твиттере один мусор из-за ботов. Мировая закулиса может и использует Твиттер для анализа настроений хомячков, но там явно используются хитрые фильтры, которые никогда не будут представлены. Так что Твиттер был и остается игрушкой.
Они все неудобные до ужаса. Проще делать предварительную обработку на Ruby или Python, запихивать обработанные данные в СУБД и в R заниматься только математикой.
Не, речь не о предсказаниях. Речь о поиске корреляции с лагом. Вручную это трудно, так как нужно перебирать вложенные контексты, да еще для разных задержек. А вот запустить поиск в цикле в R — самое оно. Пример: всплеск числа появлений слова "самолет" в новостях практически всегда сопровождается последующим изменением котировок. Только расти они могут в разные стороны. Если анализировать контекст, то самолет в контексте "крушение" уже дает изменение в заданную сторону. Но лаг положительный и нам это не интересно. А вот если еще сильнее углублять контекст, то можно найти и корреляцию с отрицательным лагом. То есть, новости сразу с 3 заданными ключевыми словами уже могут являться торговым сигналом.
Чингачгук
25 марта, 2017 - 13:57
Непонятен заголовок — причем тут Linux. R прекрасно работает под виндой, а МТ только под виндой.
Справедливости ради я не люблю винду и била
Чингачгук
20 декабря, 2017 - 17:46
автор! как ты это сделал?
У меня после строчки ошибка:
> p2 <- polyfit(x,t,2)
Error in polyfit(x, t, 2) : Arguments x and y must be numeric.
Чингачгук
8 ноября, 2018 - 23:49
Интересно почитать такое, но прогноз по этому графику, видно без всяких программ и еще чего, еще столько-же вниз...
Чингачгук
8 ноября, 2018 - 23:57
есть программы дающие очень точный прогноз, но подход совершенно другой, корреляции и ряды здесь не работают
pomodor
9 ноября, 2018 - 10:35
Нет такой программы. Во-первых, какая бы замечательная программа не была, теорию вероятности никто не отменял. Во-вторых, в изменении цены присутствует случайная компонента, которую вообще невозможно предсказать. В третьих, самое главное, если бы такая программа существовала, то ее разработчики не стали бы ее продавать, а пошли бы торговать на биржу и заработали бы трулиарды.
Комментировать